Compose
Inline AI Assistant
Rewrite, refine, and trigger document-intelligence actions directly while drafting messages.
Open-source AI workspace · Nuxt 4 + Paperless-ngx
Taan Mind connects chat, OCR, metadata enrichment, and KPI dashboards around Paperless-ngx — with local-first options through Ollama and a Docker-ready stack.
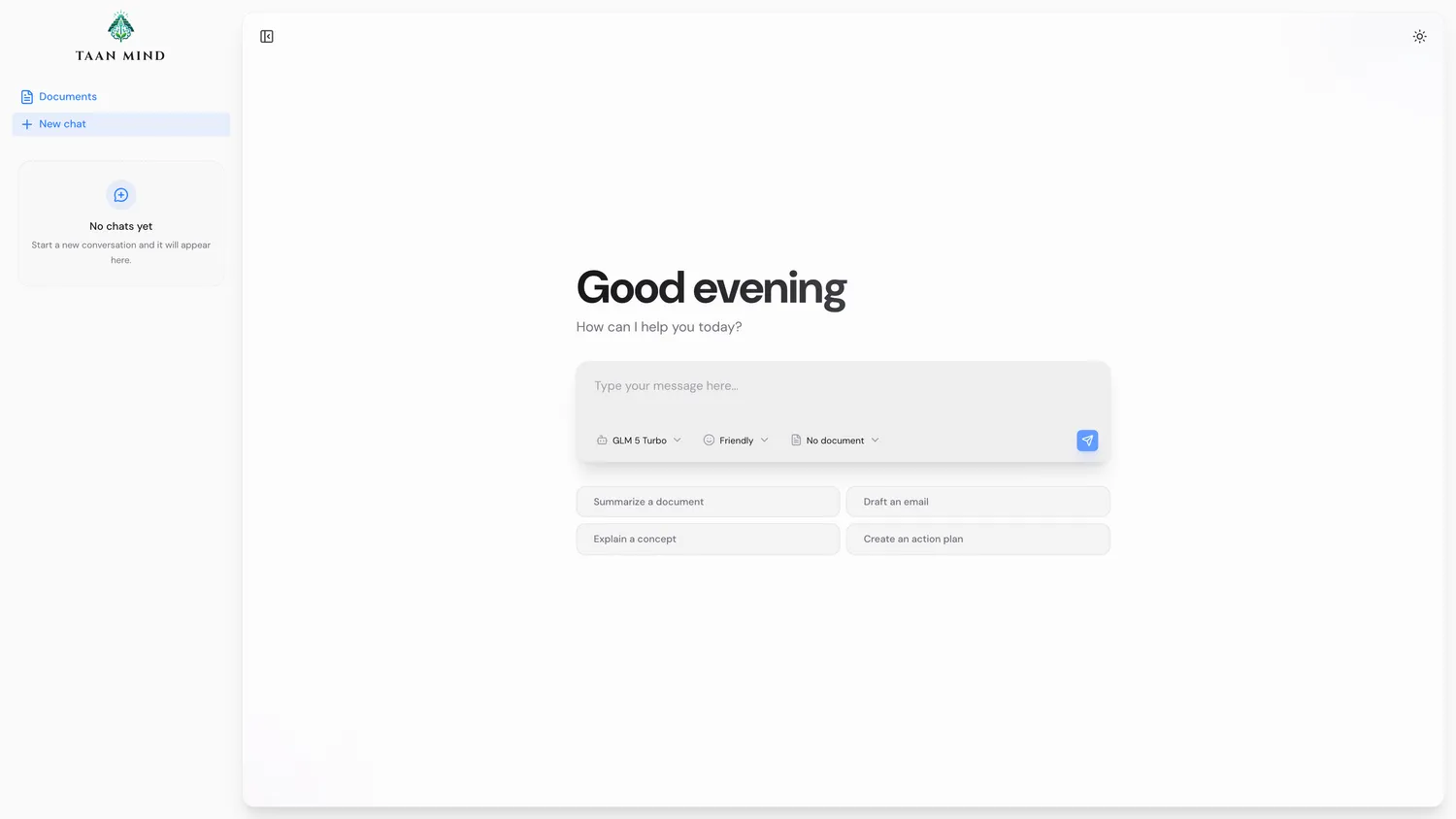
Chat, documents, OCR, and metrics in one workspace.
A technical companion for teams that want useful document AI without losing control of their files.
Privacy-focused
Designed around local storage and controlled AI providers.
Paperless companion
Uses Paperless-ngx as the durable document system.
Docker-ready
Ships with a full-stack compose workflow for evaluation.
Developer-friendly
Nuxt, Nitro APIs, typed data access, and clear boundaries.
Latest release
v1.0.15The latest Taan Mind release brings contextual AI actions into the prompt flow, while preserving the same local-first document pipeline and explicit model registry.
Rewrite, refine, and trigger document-intelligence actions directly while drafting messages.
Build assistant context from explicit document selections so answers stay tied to the right Paperless records.
Assistant actions sit above model, personality, and document selectors for a calmer workspace.
Designed for responsible document AI
Paperless-ngx → OCR → AI context → assistant actions → measured outcomes.
Product tour
Real product surfaces show the bridge between Paperless-ngx, AI chat, processing status, and KPI inspection.
How it works
The product story is simple: synchronize documents, process them with OCR and AI, then use the enriched context in chat and dashboards.
Proxy document operations and sync metadata into the app cache.
Extract text, clean content, and suggest titles, tags, correspondents, and types.
Inject document context into chat, review KPIs, and patch metadata back to Paperless.
Core capabilities
Instead of a generic feature grid, Taan Mind is easier to understand as a stack: conversation, document intelligence, and operations.
A document-aware AI chat surface with selectable providers and personalities.
Use MiniMax, GLM, Nova, and available non-OCR Ollama models.
Inject OCR/AI-processed Paperless content directly into chats.
Rewrite prompts and trigger document-intelligence actions before sending.
A processing pipeline that turns archived files into useful structured context.
CRUD, search, and binary download behind the app API.
Background extraction with Ollama OCR models and MuPDF page processing.
Suggest titles, tags, correspondents, and document types from content.
Everything needed to evaluate, run, and maintain the stack responsibly.
Charts for status, timeline, MIME type, and document type distribution.
HTTP-only session cookies with app-owned local SQLite storage.
Hardened multi-stage Dockerfile and integrated Paperless stack via Compose.
Implementation stack
The official app is built with Nuxt 4 and a pragmatic set of tools for APIs, storage, OCR, rendering, and dashboards.
Built in the open
Open source & self-hostable
Run the whole stack on your own infrastructure — no vendor lock-in, no per-seat fees. Inspect the code and contribute on GitHub.
Keep the path familiar for open-source contributors: install dependencies, copy the environment file, or launch the full Paperless stack with Docker Compose.
git clone https://github.com/zademy/taan-mind.git
cd taan-mind
pnpm install
cp .env.example .env# Build and start everything
cp .env.example .env
docker compose up -d --build
# Optional: remove the completed bootstrap container after startup
docker compose rm -f paperless-bootstrapCommunity support
Taan Mind grows through community use, feedback, maintenance, and contributions. Donations help keep improvements moving without turning the project into a closed product.